
Speed of lookup from Python data structures
Is O(1) really faster than O(n)?

Anyone who has written software before knows that looking up data by iterating through a list (or vector, or array) is a really bad idea. This is because the program has to search through all the entries in the list till it finds a match, giving this operation a time complexity of O(n), where n is the length of the list, indicating the time per lookup is linearly proportional to the length of the list. See this article for a more through description of time complexity (Big O) notation.
Fortunately it is possible to do better. Hash-tables (or hash-maps or hash-sets) use a “hash-function” to convert data into a unique “hash” which then corresponds to a “bucket” or “slot” in the hash-table. This allows us to lookup data in O(1) or constant time. This is tremendously useful, and all decent modern programming languages have an implementation of hash-tables (for example map and it’s variants in C++, dictionary and set in python).
Given the obvious superiority of O(1) over O(n), it would seem like using a hash-table when looking up data is always a good idea. However Big O notation does hide some real world complexity. To be more precise, Big O notation only describes how a function scales as n changes. There is also a constant factor(s) which can be very different even for algorithms of the same time complexity.
For example, a hash-table is a much more complex data structure than a list, and this complexity could mean that for small n it is faster to lookup by iterating through a list than using a hash-table. Why do this matter - after all if n is small it should be a very fast lookup either way. However there are some situations (For example checking if a character is a vowel1) where you may wish to make a lookup from a small dataset a very large number of times, and this performance improvement may be worth pursuing.
To unpick this situation, I compared the performance of Python’s list, set and dictionary data structures. My code generates a copy of each data structure containing the first n integers, then attempts to look up a random integer k times. The average time to look up a integer is then plotted across a range of n.
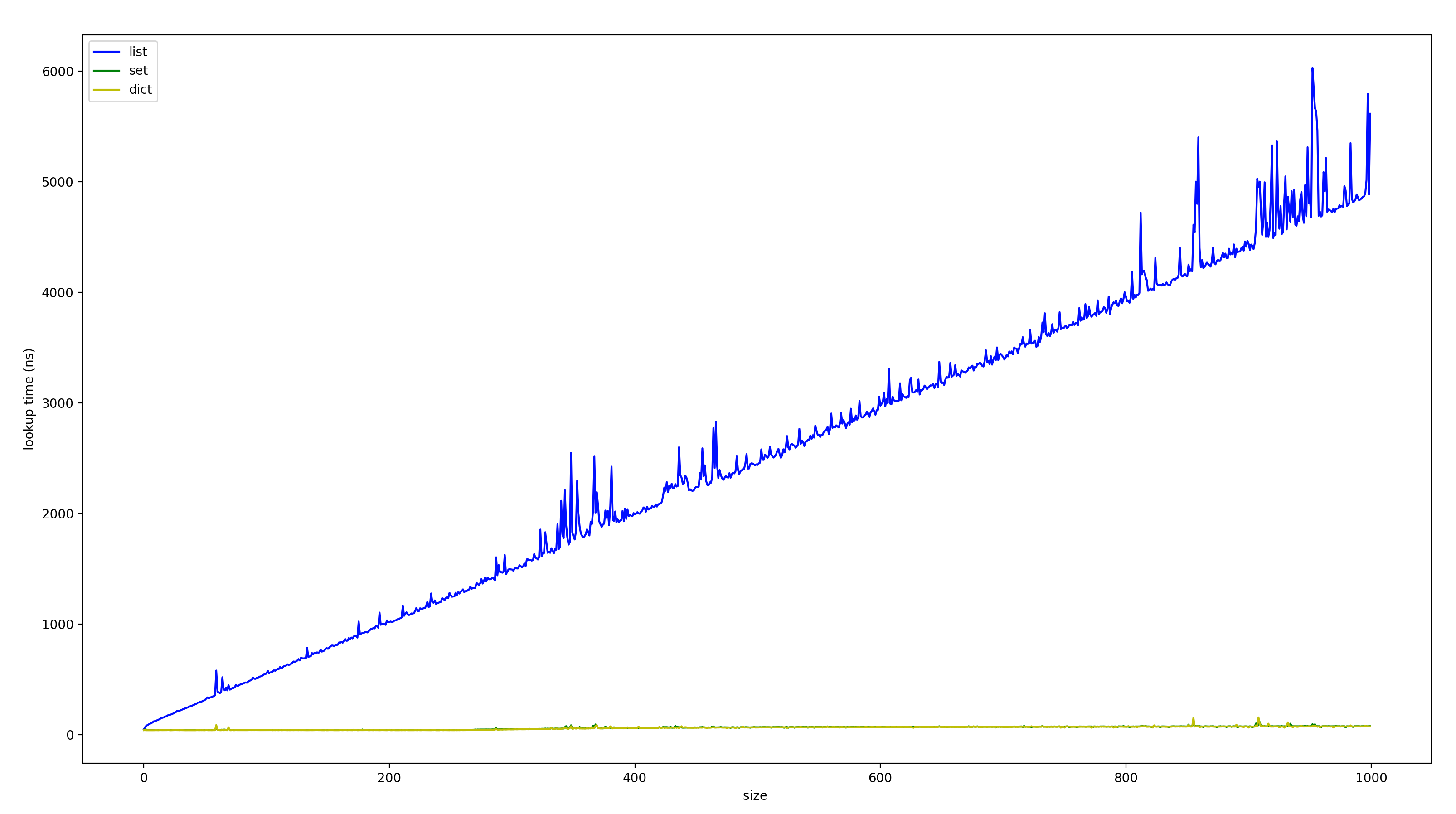
This is my result for n = 1-1000, k =10’000 (so ten thousand tests per n). We can see clearly that there is a clear linear trend for list lookups, with a slope of about 5ns per n. Meanwhile list and dict are quite clearly constant time.
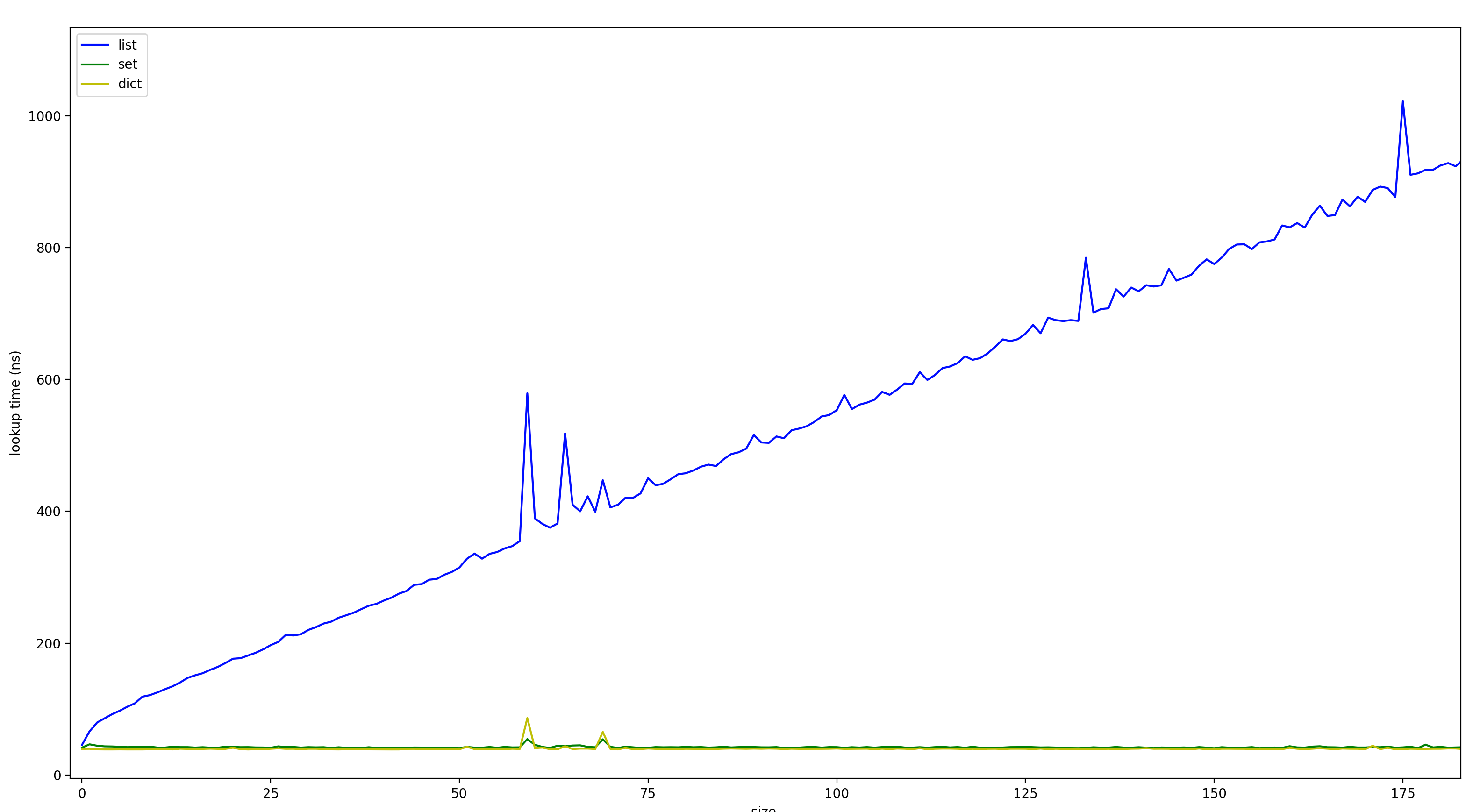
If we zoom in on small n. We can see that even for single digit n, using dictionaries or sets is still faster than list lookup via the list.index() method.
Note that even with very large k, there is still quite a bit of noise. This is because the noise is not completely random, instead it is caused by the changing performance of my computer over time (due to other programs running) and these performance changes last much longer than a single test (but shorter than running the whole program).
All these test results were obtained on a 2020 M1 Mac Mini with 8GB of RAM. Python3.12 was used. You can find my code on my Github.
You can run the code with the terminal command
Python speed_scripts.py n k Where n is the max size of list/set/dictionary to evaluate and k is the number of trials to perform per checked size. Note that the whole programming has runtime complexity(KN^2), so be wary running large values of k or n. n = 1000, k = 10’000 took my machine about 30 seconds to run.
If anybody who has non-Apple Silicon hardware wants to run these tests, please let me know and I can post the results here.
TDLR
If you are looking up random access data in python, using a dictionary or set is always faster than using list.index(), even for single digit n. And of course for larger n, sets and dictionaries are dramatically faster. So just use a dictionary/set. My testing was done on a M1 Mac, your performance may vary.
Of course if you really want good performance vowel checking, your best bet is a lookup table. So construct a boolean array where the value at each index corresponds to whether that characters numeric representation (eg ASCII code) is a vowel or not. You can then check if it’s vowel or not by checking the value in the boolean array whose index is equal to the numeric representation of the character. This allows for constant-time checking without needing any complex data structures.